
Yonggang Qi 齐勇刚
Beijing University of Posts and Telecommunications (BUPT), Beijing, China
I am an associate professor at BUPT, leading a small research group working on generative and multimodal AI, with recent publications at CVPR, ICLR, ICML, NeurIPS, and IJCV. I received my PhD in Signal Processing from BUPT in 2015, advised by Professor Jun Guo at the Pattern Recognition and Intelligent Systems (PRIS) Laboratory. From 2019 to 2020, I was a visiting scholar at SketchX Lab, headed by Dr. Yi-Zhe Song, at the Centre for Vision, Speech and Signal Processing (CVSSP), University of Surrey. I was also a guest PhD at Aalborg University, Denmark in 2013, and a visiting researcher at Sun Yat-sen University, China in 2014.
My research lies at the intersection of computer vision, generative modeling, and multimodal learning. Recent work focuses on (i) scalable generative models for video and 3D (autoregressive & diffusion), (ii) geometry- and physics-aware world modeling, (iii) chain-of-thought reasoning for embodied tasks such as vision-language navigation, and (iv) post-training of diffusion models with reinforcement learning. Earlier work centered on free-hand sketch as a window into human visual abstraction.
拟招收2027年博士研究生一名(申请-考核、硕博连读),欢迎带简历邮件联系。
常年招收2-4名硕士研究生(保研+考研)、科研实习生若干名(3-6个月及以上),欢迎有科研热情的同学带简历邮件联系。
News
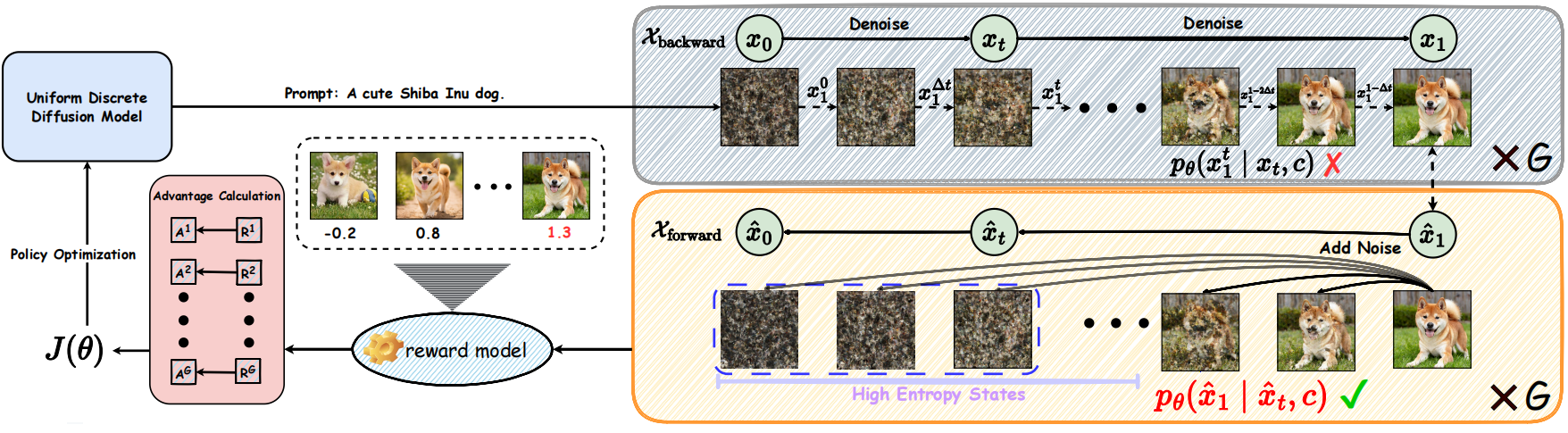
- 2026-05: One paper (Uniform Discrete Diffusion Model + GRPO) is accepted by ICML 2026 as Spotlight!
- 2026-03: I am invited as an Area Chair (AC) for NeurIPS 2026.
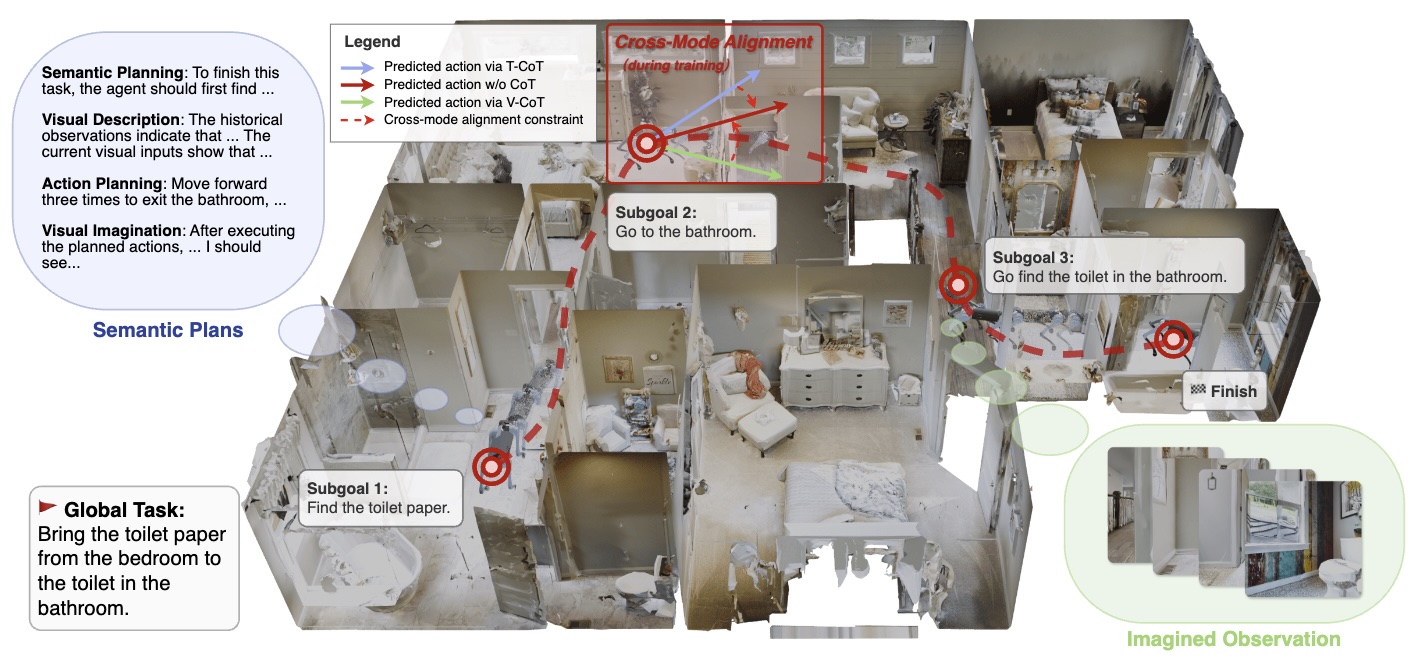
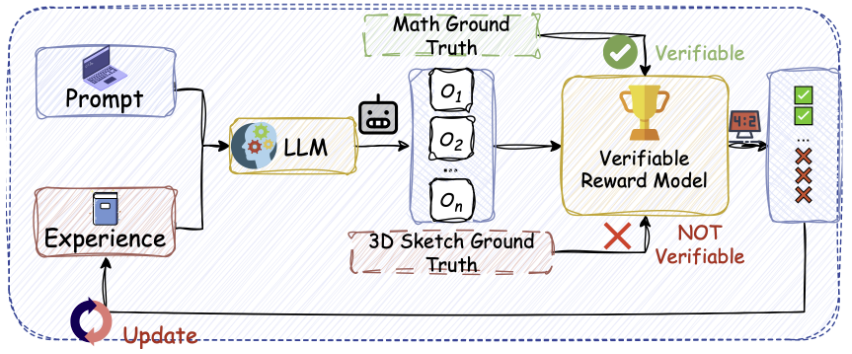
- 2026-02: Two papers (CoT for VLN & LLM for 3D Drawing) including one Highlight to appear in CVPR 2026!
- 2026-02: One paper (Complex Sketch Generation) is accepted by IJCV!
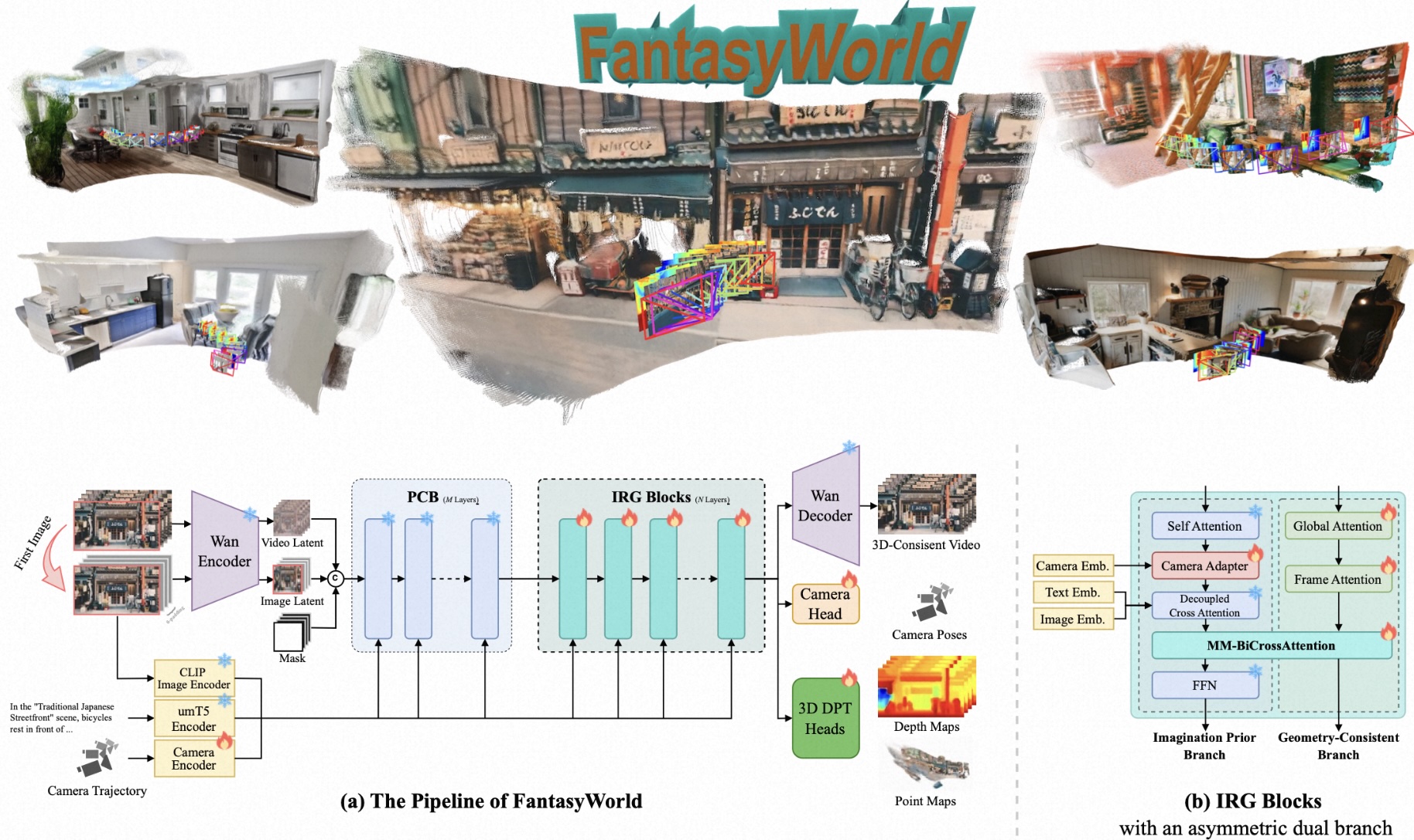
- 2026-01: One paper (World Model) to appear in ICLR 2026!
- 2026-01: I am invited as an Area Chair (AC) for ICPR 2026!
- 2025-09: Two papers (Dense Semantic Matching & Diffusion Inversion) to appear in NeurIPS 2025!
- 2025-08: I will serve as an Area Chair (AC) for ICLR 2026!
- 2025-07: One paper (Talking video generation) to appear in ACM MM 2025. Check it here of our GitHub repo.
- 2025-01: One paper (Video generation) to appear in ICLR 2025.
- 2024-12: Two papers (Edge detection & Text-to-image generation) to appear in AAAI 2025 including one Oral!
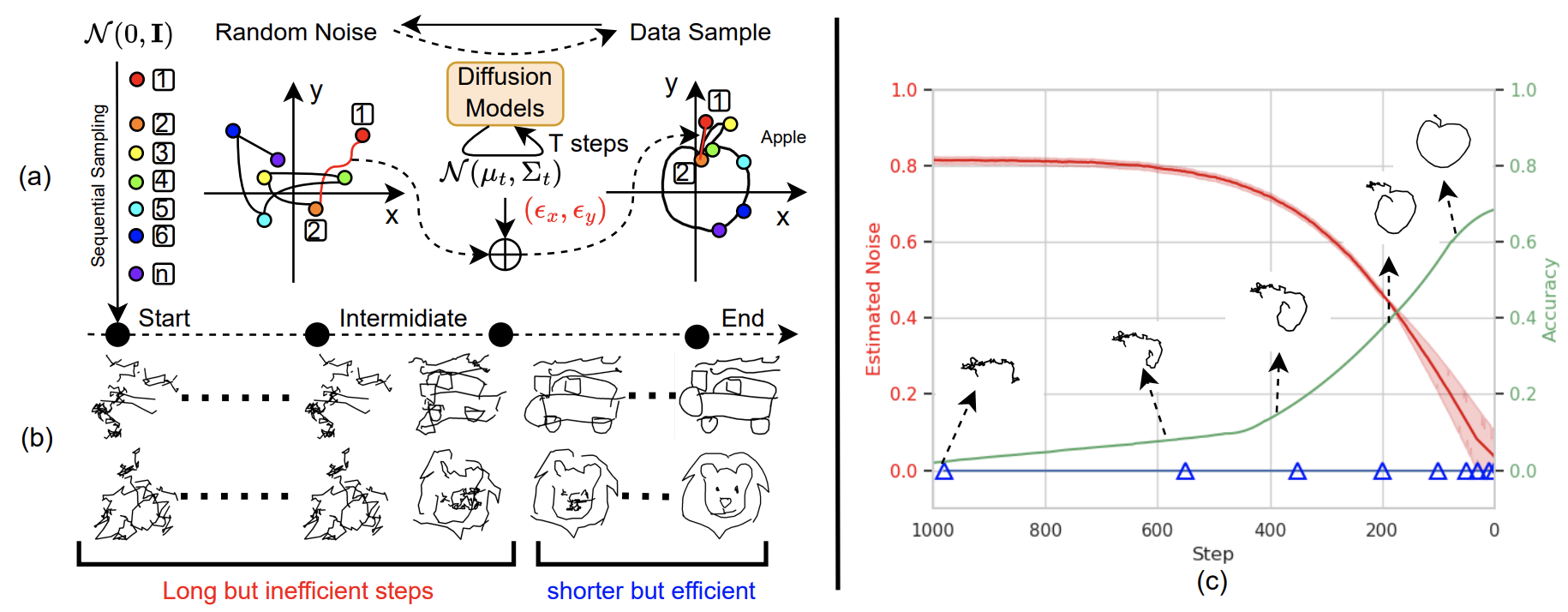
- 2024-01: One paper (Sketch generation) to appear in ICLR 2024.
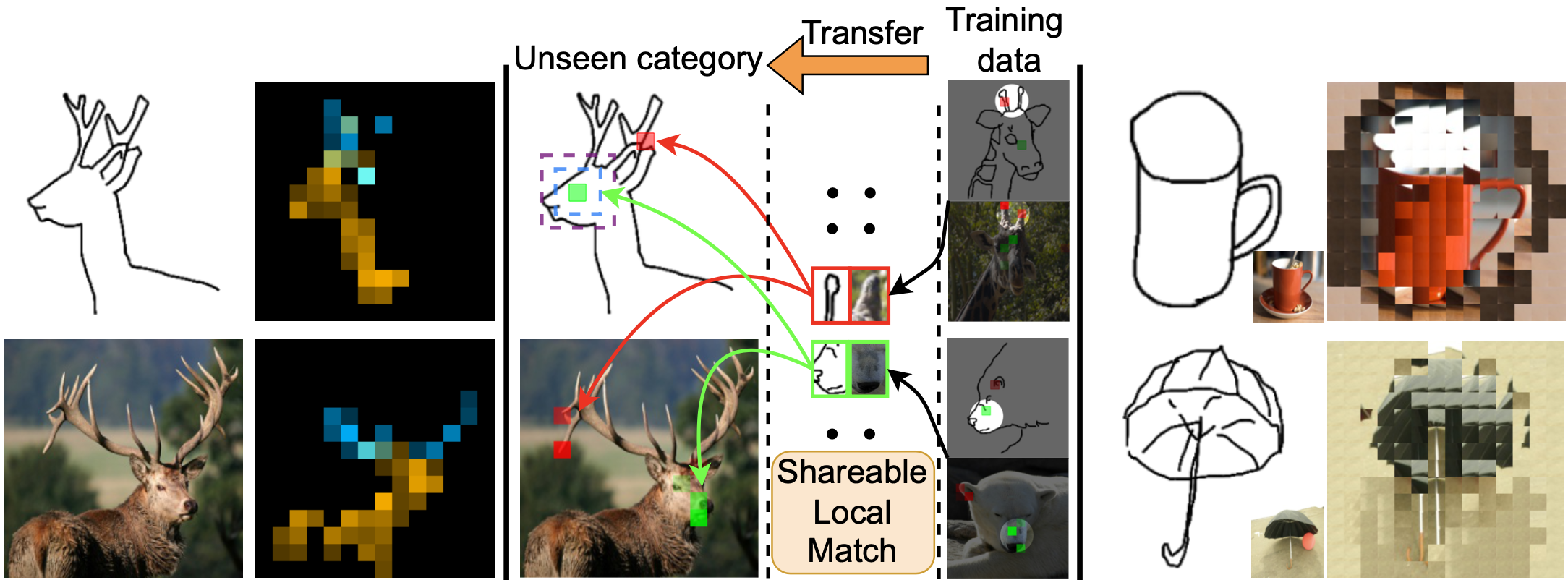
- 2023-03: One paper about explainable ZS-SBIR to appear in CVPR 2023 as a highlight!
- 2023-01: Our work on vectorized sketch generation with diffusion model to appear in ICLR 2023 (Spotlight).
- 2022-10: Our work on sketch to image generation using diffusion model is accepted by BMVC 2022.
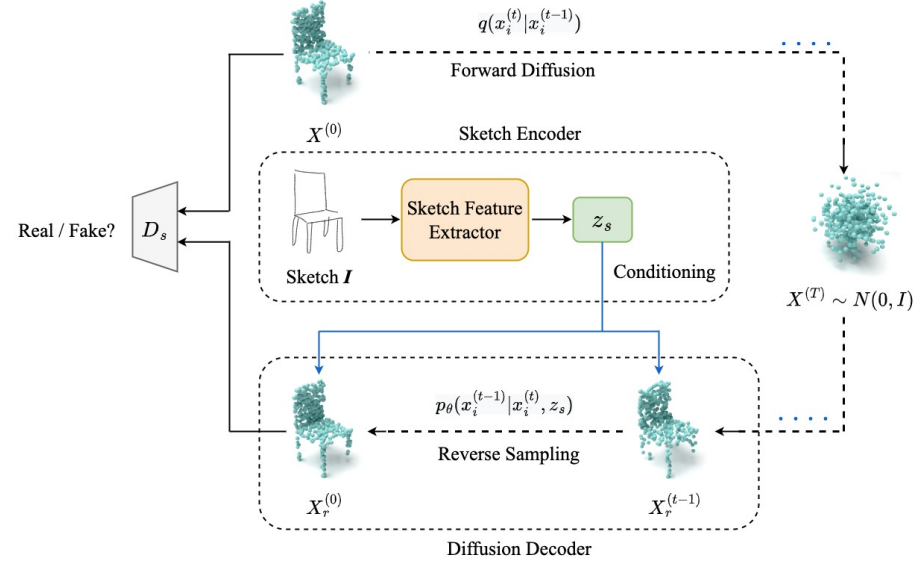
- 2022-09: One work about sketch to point cloud generation is accepted by ACCV 2022 (Oral)!
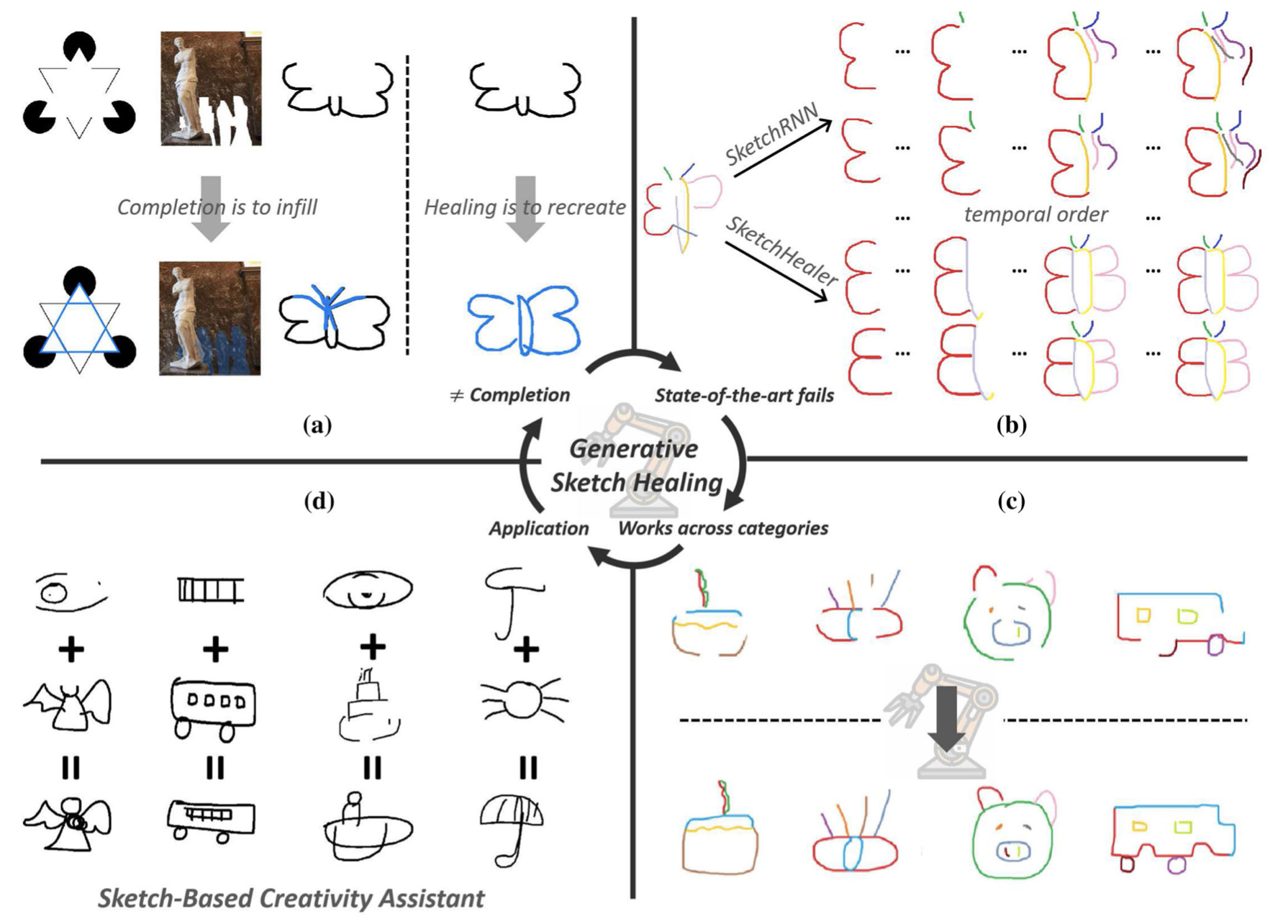
- 2022-04: Our work Generative Sketch Healing is accepted by IJCV!
- 2022-04: I am co-organizing the 2nd workshop on Sketching for Human Expressivity (SHE) at ECCV'22!
- 2021-12: Promoted to an associate professor.
- 2021-10: One paper on sketch-based 3D shape retrieval (SBSR) with a new fine-grained SBSR dataset got accepted by TIP!
- 2021-07: One paper on latticed sketch representation for sketch manipulation got accepted by ICCV 2021! Code and pre-trained models are publicly available now.
- 2021-04: I am co-organizing 1st workshop on Sketching for Human Expressivity (SHE) at ICCV'21!
- 2021-03: One paper on perceptual reasoning got accepted by CVPR 2021!
- 2020-11: One journal paper got accepted by IEEE TCSVT.
- 2020-08: One paper is accepted at BMVC 2020 as oral presentation.
- 2020-03: Two papers got accepted by IEEE ICME 2020.
- 2019-12: One journal paper got accepted by IEEE TCSVT.
- 2019-11: Moved to UK and started my visiting at CVSSP in University of Surrey!
- 2019-08: One paper got accepted by IEEE VCIP 2019.
- 2019-05: Got sponsorship from Chinese Scholarship Council (CSC) for visiting SketchX Lab at CVSSP in University of Surrey for one year!
Selected Publications


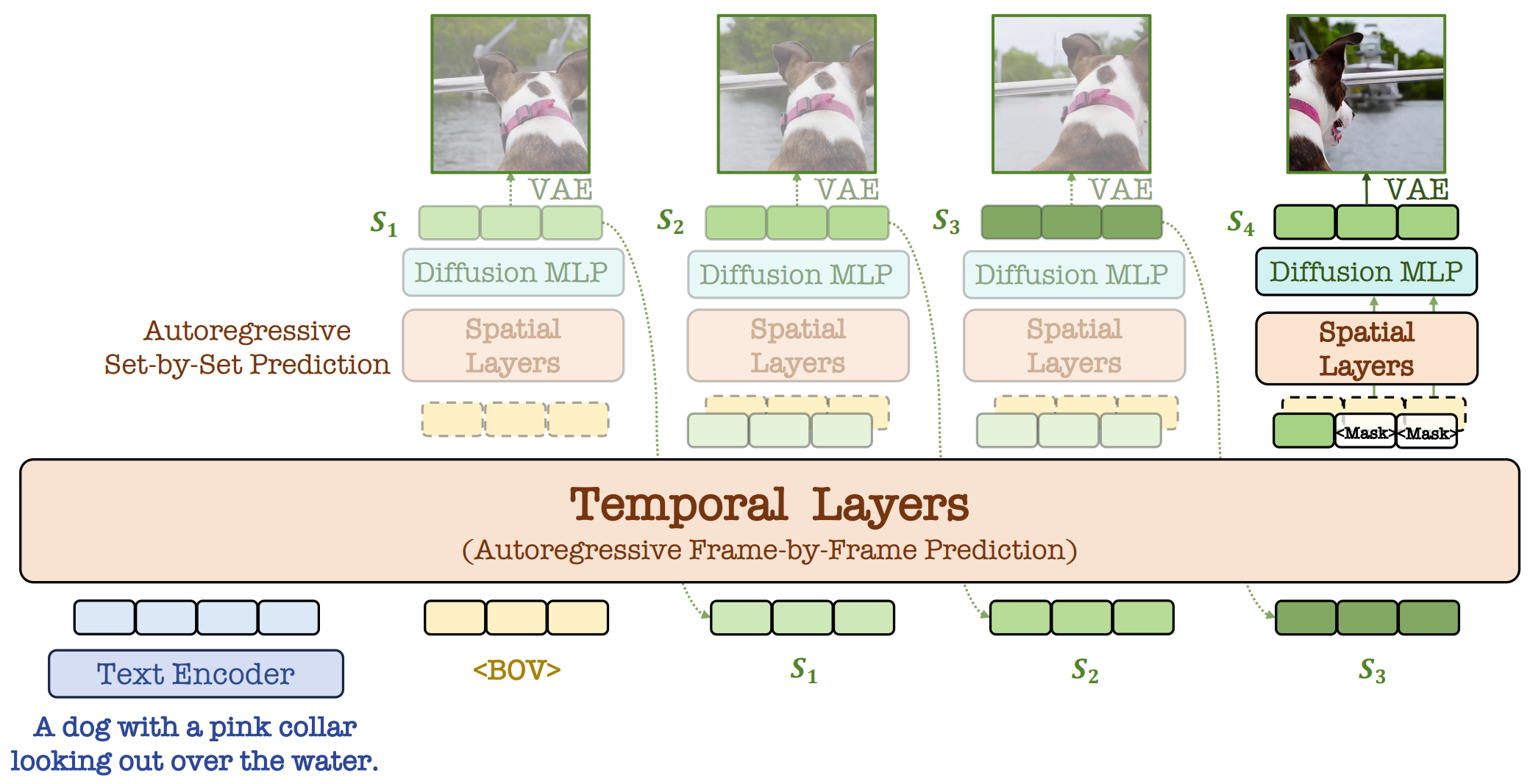
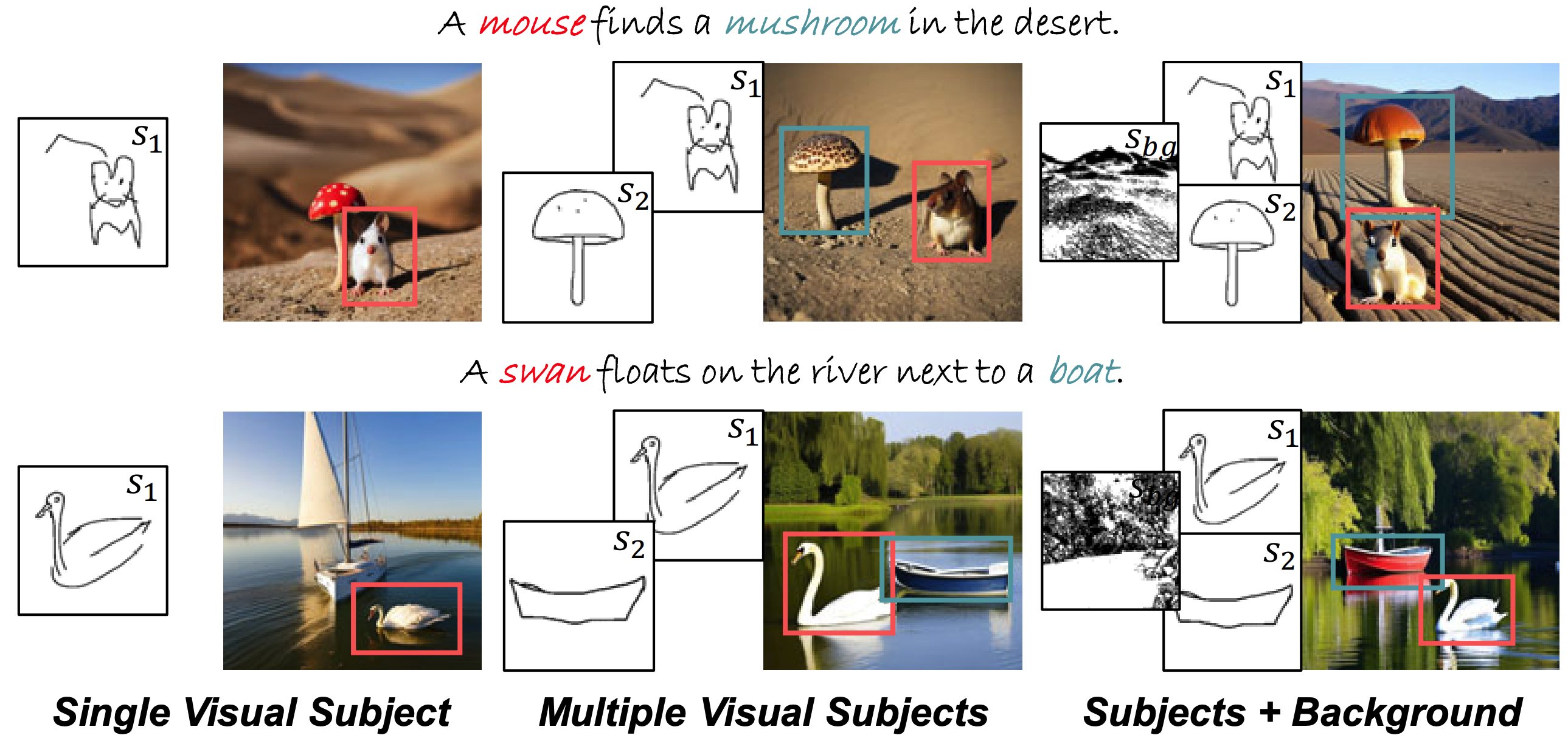
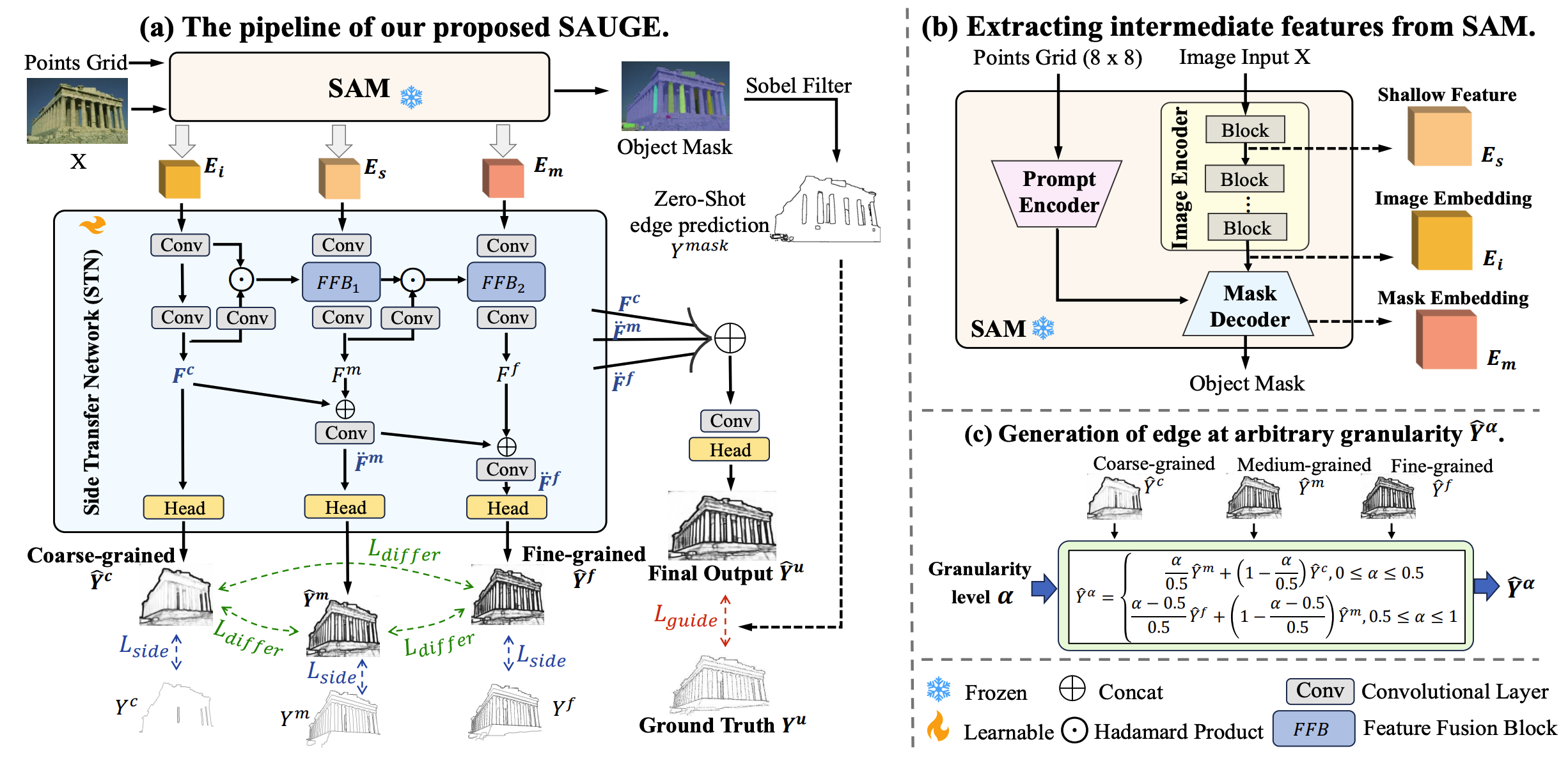
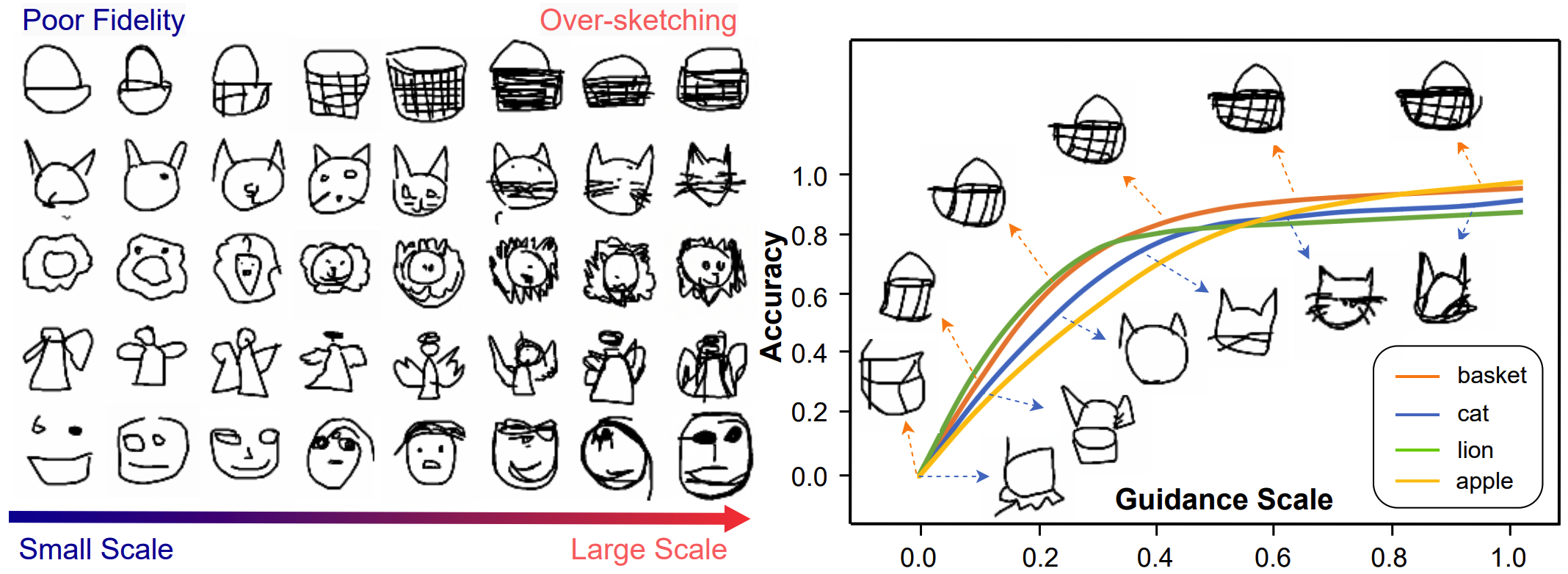




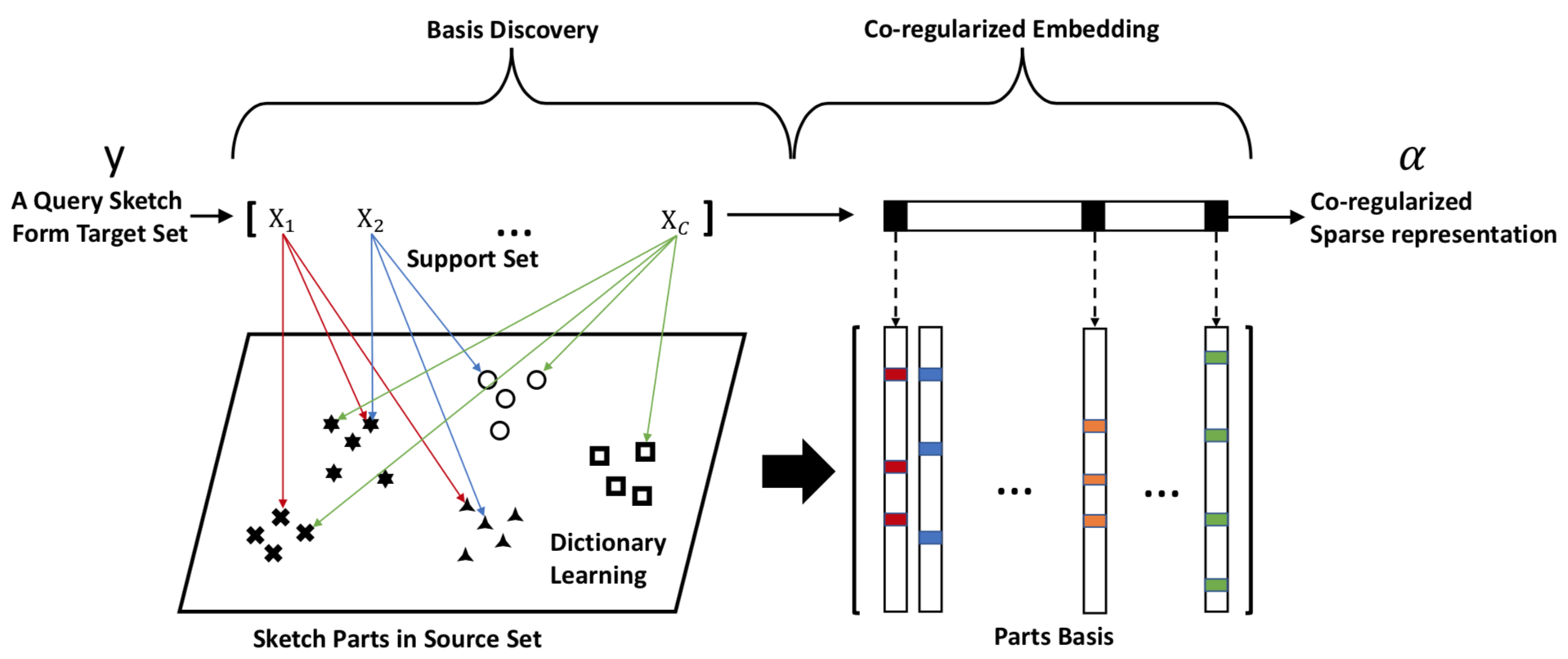
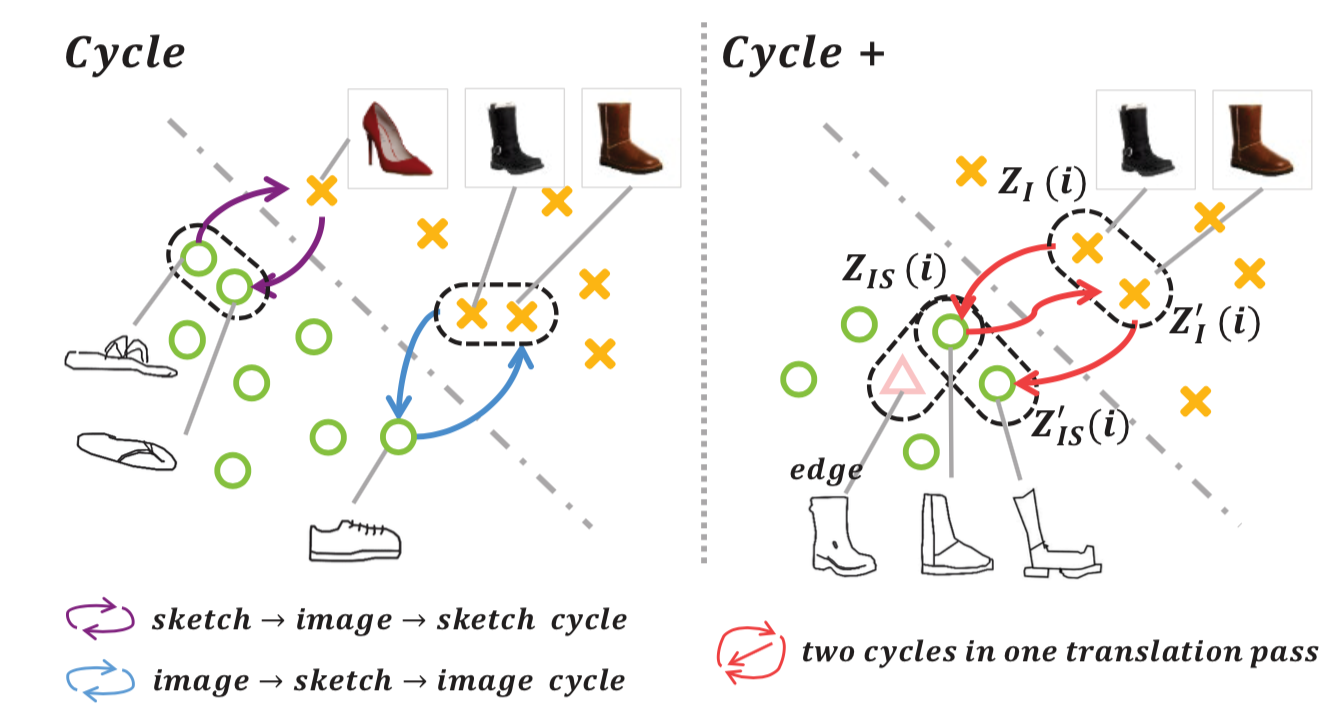
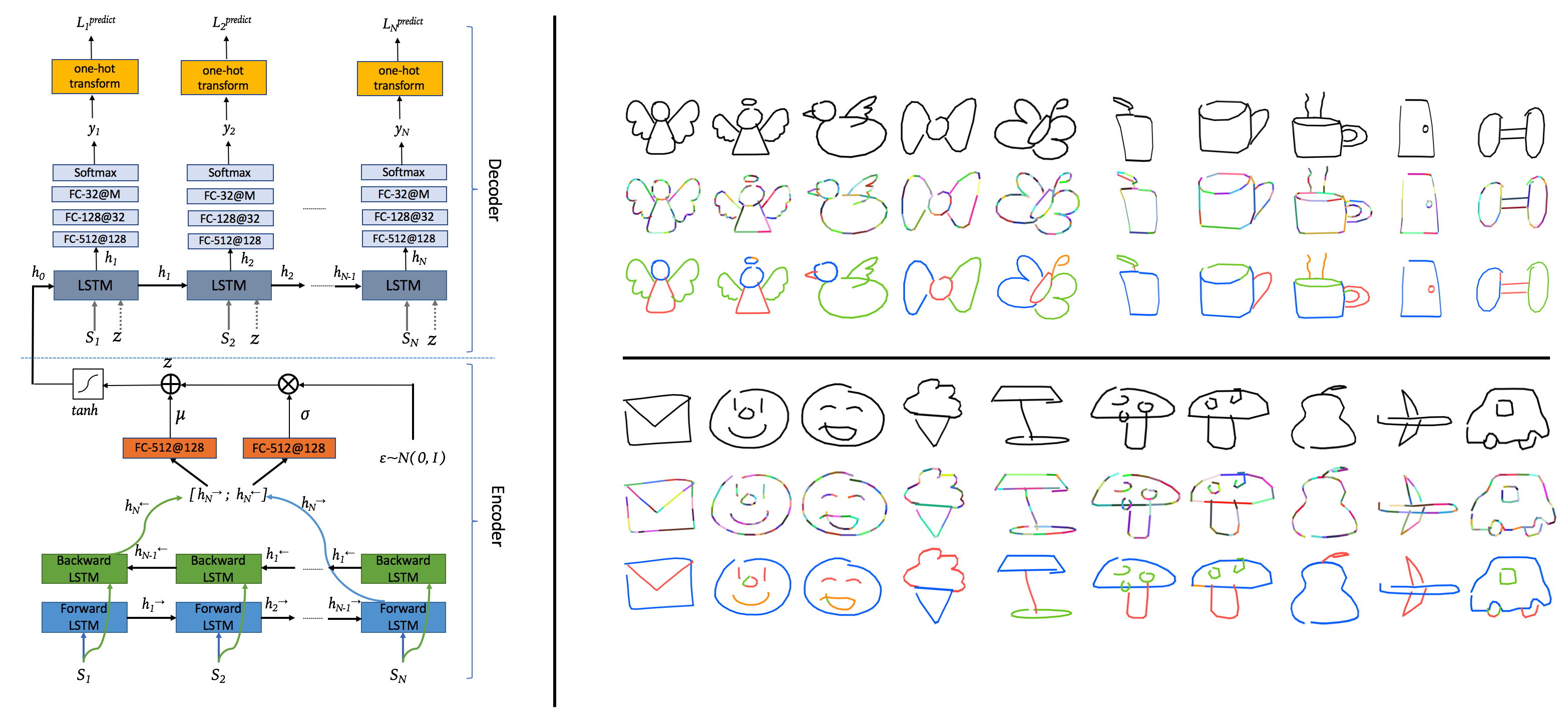
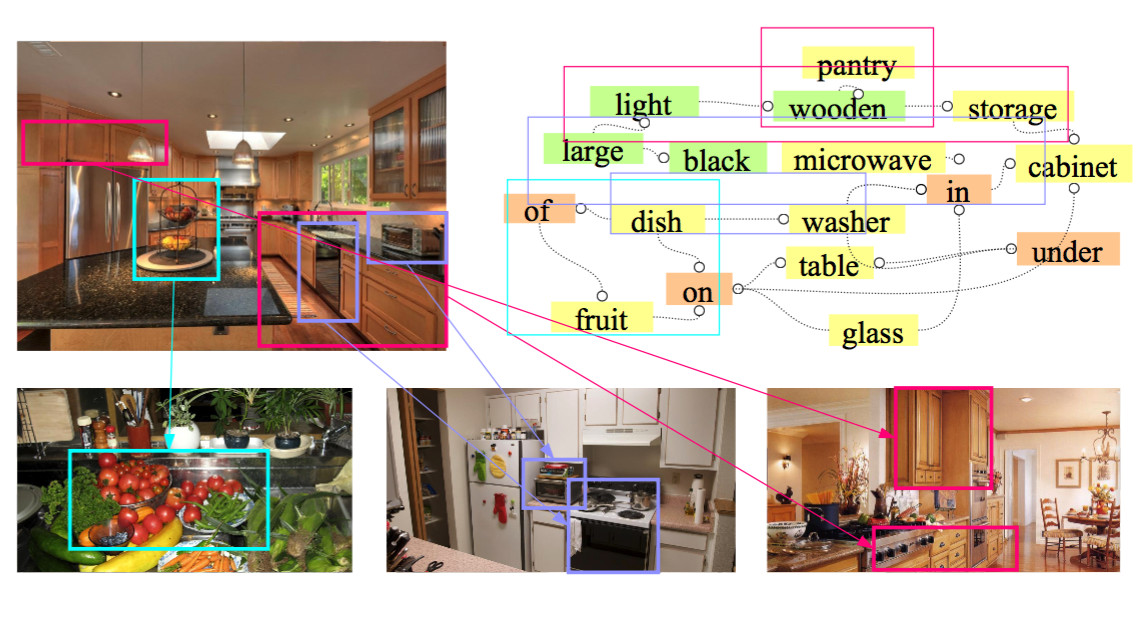


Team Members
PhD Students




Master Students










Alumni
Master Students
- 邓皓戈 (Haoge Deng)
- 代欣 (Xin Dai)
- 汪强 (Qiang Wang)
- 卢婷 (Ting Lu)
- 林峰印 (Fengyin Lin)
- 孔迪 (Di Kong)
- 刘达 (Da Liu)
- 李明康 (Mingkang Li)
- 陈彦岚 (Yanlan Chen)
- 吴宙思 (Zhusi Wu)
- 张楷 (Kai Zhang)
- 苏国耀 (Guoyao Su)
- 王尤嘉 (Youjia Wang)
- 程闱邵 (Weishao Cheng)
Updated May. 2026, page created using Bootstrap